Logistic Regression_3
Question
For this exercise, you will use logistic regression and neural networks to recognize handwritten digits (from 0 to 9). Automated handwritten digit recognition is widely used today - from recognizing zip codes (postal codes) on mail envelopes to recognizing amounts written on bank checks. This exercise will show you how the methods you’ve learned can be used for this classification task. In the first part of the exercise, you will extend your previous implementation of logistic regression and apply it to one-vs-all classification.
理论基础
底层理论跟普通的逻辑回归没什么不同,只是分类的标签变成了10个,一个图片仅拥有一个标签。像这样的数字或字母识别我们生活中经常用到。(当然更多情况是一个物体对应很多标签,要进行那样的智能识别需要较大的数据和计算,经常用神经网络去完成)对于本题采用逻辑回归的分类,我们只需要将之前的向量Theta变为列数为10的向量组即可。进行训练时,训练集中图片所示数字对应的y值设置为1就行(图片为3,则y_3=1,其余为0)。最终X与Theta相乘能得到一个长度为10的结果数组。每个数各代表对应序号的数字的可能性大小,取数组中最大的数即可作为模型预测结果。(本文将1对应于序号1,2对应于序号2,….,但0对应于序号10)
$$
\Theta=\begin{bmatrix}
\Theta_{1} & \Theta_{2} & … & \Theta_{10}
\end{bmatrix}\\
$$
$$
\Theta_{i}=\begin{bmatrix}\theta_{0}^{i}\\
\theta_{1}^{i}\\
…\\
\theta_{400}^{i}
\end{bmatrix}
$$
400是因为本题所给图片以20×20的数据形式保存,拉长成一维数组后有400个数据,外加一个“常数项” theta_0,Theta中一列共401个数据。
数据读取处理
1 | import numpy as np |
{'__header__': b'MATLAB 5.0 MAT-file, Platform: GLNXA64, Created on: Sun Oct 16 13:09:09 2011',
'__version__': '1.0',
'__globals__': [],
'X': array([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]),
'y': array([[10],
[10],
[10],
...,
[ 9],
[ 9],
[ 9]], dtype=uint8)}
1 | type(data) |
1 | def plot_an_image(X): |
1 | plot_an_image(raw_X) |
1 | def plot_100_image(X): |
1 | plot_100_image(raw_X) |

损失函数与梯度下降
1 | def sigmoid(z): |
1 | def costFunction(theta,X,y,lamda): |
1 | def gradient_reg(theta,X,y,lamda): |
1 | X=np.insert(raw_X,0,values=1,axis=1) |
模型生成
1 | from scipy.optimize import minimize |
1 | lamda=1 |
array([[-2.38187334e+00, 0.00000000e+00, 0.00000000e+00, ...,
1.30433279e-03, -7.29580949e-10, 0.00000000e+00],
[-3.18303389e+00, 0.00000000e+00, 0.00000000e+00, ...,
4.46340729e-03, -5.08870029e-04, 0.00000000e+00],
[-4.79638233e+00, 0.00000000e+00, 0.00000000e+00, ...,
-2.87468695e-05, -2.47395863e-07, 0.00000000e+00],
...,
[-7.98700752e+00, 0.00000000e+00, 0.00000000e+00, ...,
-8.94576566e-05, 7.21256372e-06, 0.00000000e+00],
[-4.57358931e+00, 0.00000000e+00, 0.00000000e+00, ...,
-1.33390955e-03, 9.96868542e-05, 0.00000000e+00],
[-5.40542751e+00, 0.00000000e+00, 0.00000000e+00, ...,
-1.16613537e-04, 7.88124085e-06, 0.00000000e+00]])
预测结果准确率
将预测结果1的位置与图片实际的数字序号(1)的位置进行比对,相同则记1,不同则记0。将结果累加并除以测试用数据个数,即可得到准确率。
1 | def predict(X,theta_final): |
1 | y_pred=predict(X,theta_final) |
实际图片与预测结果的比对
该模型用训练集进行检测准确率为0.9446,从下面随机选取的10个样本可以看见,该模型错把一个5认成了9。
1 | def plot_an_image_test(X,X_2): |
1 | for i in range(10): |
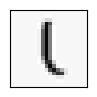

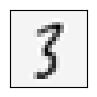



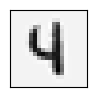



Site
代码(Jupyter)和所用数据:https://github.com/codeYu233/Study/tree/main/Logistic%20Regression_3
Note
该题与数据集均来源于Coursera上斯坦福大学的吴恩达老师机器学习的习题作业,学习交流用,如有不妥,立马删除
